Tutoriel Django - 6e partie : Vues génériques pour les listes et les détails
| Prérequis: |
Avoir terminé tous les tutoriels précédents, y compris Django Tutorial Part 5: Creating our home page. |
|---|---|
| Objectif: |
Comprendre où et comment utiliser des vues génériques basées sur classes, et comment extraire des patterns dans des URLs pour transmettre les informations aux vues. |
Aperçu
Dans ce tutoriel, nous allons terminer la première version du site web LocalLibrary, en ajoutant des pages de listes et de détails pour les livres et les auteurs (ou pour être plus précis, nous allons vous montrer comment implémenter les pages concernant les livres, et vous faire créer vous-mêmes les pages concernant les auteurs !).
Le processus est semblable à celui utilisé pour créer la page d'index, processus que nous avons montré dans le tutoriel précédent. Nous allons avoir de nouveau besoin de créer des mappages d'URLs, des vues et des templates. La principale différence est que, pour la page des détails, nous allons avoir le défi supplémentaire d'extraire de l'URL des informations que nous transmettrons à la vue. Pour ces pages, nous allons montrer comment utiliser un type de vue complètement différent : des vues "listes" et "détails" génériques et basées sur des classes. Cela peut réduire significativement la somme de code nécessaire, les rendant ainsi faciles à écrire et à maintenir.
La partie finale de ce tutoriel montrera comment paginer vos données quand vous utilisez des vues "listes" génériques basées sur des classes.
Page de liste de livres
La page de liste des livres va afficher une liste de tous les enregistrements de livres disponibles, en utilisant l'URL: catalog/books/. La page va afficher le titre et l'auteur pour chaque enregistrement, et le titre sera un hyperlien vers la page de détails associée. La page aura la même structure et la même zone de navigation que les autres pages du site, et nous pouvons dès lors étendre le template de base (base_generic.html) que nous avons créé dans le tutoriel précédent.
Mappage d'URL
Ouvrez le fichier /catalog/urls.py, et copiez-y la ligne en gras ci-dessous. Comme pour la page d'index, cette fonction path() définit un pattern destiné à identifier l'URL ('books/'), une fonction vue qui sera appelée si l'URL correspond (views.BookListView.as_view()), et un nom pour ce mappage particulier.
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
]
Comme discuté dans le tutoriel précédent, l'URL doit auparavant avoir identifié la chaîne /catalog, aussi la vue ne sera réellement appelée que pour l'URL complète: /catalog/books/.
La fonction vue a un format différent de celui que nous avions jusqu'ici : c'est parce que cette vue sera en réalité implémentée sous forme de classe. Nous allons la faire hériter d'une fonction vue générique existante, qui fait la plus grande partie de ce que nous souhaitons réaliser avec cette vue, plutôt que d'écrire notre propre fonction à partir de zéro.
En Django, on accède à la fonction appropriée d'une vue basée sur classe en appelant sa méthode de classe as_view(). Cela a pour effet de créer une instance de la classe, et de s'assurer que les bonnes méthodes seront appelées lors de requêtes HTTP.
Vue (basée sur classe)
Nous pourrions assez aisément écrire la vue "liste de livres" comme une fonction ordinaire (comme notre précédente vue "index"), qui interrogerait la base de données pour tous les livres, et qui ensuite appellerait render() pour passer la liste à un template spécifique. À la place, cependant, nous allons utiliser une vue "liste" générique, basée sur une classe (ListView), une classe qui hérite d'une vue existante. Parce que la vue générique implémente déjà la plupart des fonctionnalités dont nous avons besoin et suit les meilleures pratiques Django, nous pourrons créer une vue "liste" plus robuste avec moins de code, moins de répétition, et au final moins de maintenance.
Ouvrez le fichier catalog/views.py, et copiez-y le code suivant à la fin :
from django.views import generic
class BookListView(generic.ListView):
model = Book
C'est tout ! La vue générique va adresser une requête à la base de données pour obtenir tous les enregistrements du modèle spécifié (Book), et ensuite rendre un template situé à l'adresse /locallibrary/catalog/templates/catalog/book_list.html (que nous allons créer ci-dessous). À l'intérieur du template vous pouvez accéder à la liste de livres grâce à la variable de template appelée object_list OU book_list (c'est-à-dire l'appellation générique "the_model_name_list").
Note : Ce chemin étrange vers le lieu du template n'est pas une faute de frappe : les vues génériques cherchent les templates dans /application_name/the_model_name_list.html (catalog/book_list.html dans ce cas) à l'intérieur du répertoire /application_name/templates/ (/catalog/templates/).
Vous pouvez ajouter des attributs pour changer le comportement par défaut utilisé ci-dessus. Par exemple, vous pouvez spécifier un autre fichier de template si vous souhaitez avoir plusieurs vues qui utilisent ce même modèle, ou bien vous pourriez vouloir utiliser un autre nom de variable de template, si book_list n'est pas intuitif par rapport à l'usage que vous faites de vos templates. Probablement, le changement le plus utile est de changer/filtrer le sous-ensemble des résultats retournés : au lieu de lister tous les livres, vous pourriez lister les 5 premiers livres lus par d'autres utilisateurs.
class BookListView(generic.ListView):
model = Book
context_object_name = 'my_book_list' # your own name for the list as a template variable
queryset = Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
template_name = 'books/my_arbitrary_template_name_list.html' # Specify your own template name/location
Ré-écrire des méthodes dans des vues basées sur classes
Bien que nous n'ayons pas besoin de le faire ici, sachez qu'il vous est possible de ré-écrire des méthodes de classe.
Par exemple, nous pouvons ré-écrire la méthode get_queryset() pour changer la liste des enregistrements retournés. Cette façon de faire est plus flexible que simplement définir l'attribut queryset, comme nous l'avons fait dans le précédent fragment de code (bien qu'il n'y ait pas vraiment d'intérêt dans ce cas) :
class BookListView(generic.ListView):
model = Book
def get_queryset(self):
return Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
Nous pourrions aussi réécrire get_context_data(), afin d'envoyer au template des variables de contexte supplémentaires (par défaut c'est la liste de livres qui est envoyée). Le bout de code ci-dessous montre comment ajouter une variable appelée "some_data" au contexte (elle sera alors accessible comme variable de template).
class BookListView(generic.ListView):
model = Book
def get_context_data(self, **kwargs):
# Call the base implementation first to get the context
context = super(BookListView, self).get_context_data(**kwargs)
# Create any data and add it to the context
context['some_data'] = 'This is just some data'
return context
Quand vous faites cela, il est important de suivre la procédure indiquée ci-dessus :
- D'abord récupérer auprès de la superclasse le contexte existant.
- Ensuite ajouter la nouvelle information de contexte.
- Enfin retourner le nouveau contexte (mis à jour).
Note : Voyez dans Built-in class-based generic views (doc de Django) pour avoir beaucoup plus d'exemples de ce que vous pouvez faire.
Créer le template pour la Vue Liste
Créez le fichier HTML /locallibrary/catalog/templates/catalog/book_list.html, et copiez-y le texte ci-dessous. Comme nous l'avons dit ci-dessus, c'est ce fichier que va chercher par défaut la classe générique "liste" basée sur une vue (dans le cas d'un modèle appelé Book, dans une application appelée catalog).
Les templates pour vues génériques sont exactement comme les autres templates (cependant, bien sûr, le contexte et les informations envoyées au templates peuvent être différents). Comme pour notre template index, nous étendons notre template de base à la première ligne, et remplaçons ensuite le bloc appelé content.
{% extends "base_generic.html" %}
{% block content %}
<h1>Book List</h1>
{% if book_list %}
<ul>
{% for book in book_list %}
<li>
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
</li>
{% endfor %}
</ul>
{% else %}
<p>There are no books in the library.</p>
{% endif %}
{% endblock %}
La vue envoie le contexte (liste de livres), en utilisant par défaut les alias object_list et book_list ; l'un et l'autre fonctionnent.
Exécution conditionnelle
Nous utilisons les balises de templates if, else, et endif pour vérifier que la book_list a été définie et n'est pas vide. Si book_list est vide, alors la condition else affiche un texte expliquant qu'il n'y a pas de livres à lister. Si book_list n'est pas vide, nous parcourons la liste de livres.
{% if book_list %}
<!-- code here to list the books -->
{% else %}
<p>There are no books in the library.</p>
{% endif %}
La condition ci-dessus ne vérifie qu'un seul cas, mais vous pouvez ajouter d'autres tests grâce à la balise de template elif (par exemple {% elif var2 %}). Pour plus d'information sur les opérateurs conditionnels, voyez ici : if, ifequal/ifnotequal, et ifchanged dans Built-in template tags and filters (Django Docs).
Boucles for
Le template utilise les balises de template for et endfor pour boucler à travers la liste de livres, comme montré ci-dessous. Chaque itération peuple la variable de template book avec l'information concernant l'élément courant de la liste.
{% for book in book_list %}
<li> <!-- code here get information from each book item --> </li>
{% endfor %}
Bien que nous ne l'utilisions pas ici, Django, à l'intérieur de la boucle, va aussi créer d'autres variables que vous pouvez utiliser pour suivre l'itération. Par exemple, vous pouvez tester la variable forloop.last pour réaliser une action conditionnelle au dernier passage de la boucle.
Accéder aux variables
Le code à l'intérieur de la boucle crée un élément de liste pour chaque livre, élément qui montre à la fois le titre (comme lien vers la vue détail, encore à créer), et l'auteur.
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
Nous accédons aux champs de l'enregistrement "livre" associé, en utilisant la notation "à points" (par exemple book.title et book.author), où le texte suivant l'item book est le nom du champ (comme défini dans le modèle).
Nous pouvons aussi appeler des fonctions contenues dans le modèle depuis l'intérieur de notre template — dans ce cas nous appelons Book.get_absolute_url() pour obtenir une URL que vous pouvez utiliser pour afficher dans la vue détail l'enregistrement associé. Cela fonctionne, pourvu que la fonction ne comporte pas d'arguments (il n'y a aucun moyen de passer des arguments !).
Note : Il nous faut être quelque peu attentifs aux "effets de bord" quand nous appelons des fonctions dans nos templates. Ici nous récupérons simplement une URL à afficher, mais une fonction peut faire à peu près n'importe quoi — nous ne voudrions pas effacer notre base de données (par exemple) juste parce que nous avons affiché notre template !
Mettre à jour le template de base
Ouvrez le template de base (/locallibrary/catalog/templates/base_generic.html) et insérez {% url 'books' %} dans le lien URL pour All books, comme indiqué ci-dessous. Cela va afficher le lien dans toutes les pages (nous pouvons mettre en place ce lien avec succès, maintenant que nous avons créé le mappage d'URL "books").
<li><a href="{% url 'index' %}">Home</a></li>
<li><a href="{% url 'books' %}">All books</a></li>
<li><a href="">All authors</a></li>
À quoi cela ressemble-t-il ?
Vous ne pouvez pas encore construire la liste des livres, car il nous manque toujours une dépendance, à savoir le mappage d'URL pour la page de détail de chaque livre, qui est requise pour créer des hyperliens vers chaque livre. Nous allons montrer les vues liste et détail après la prochaine section.
Page de détail d'un livre
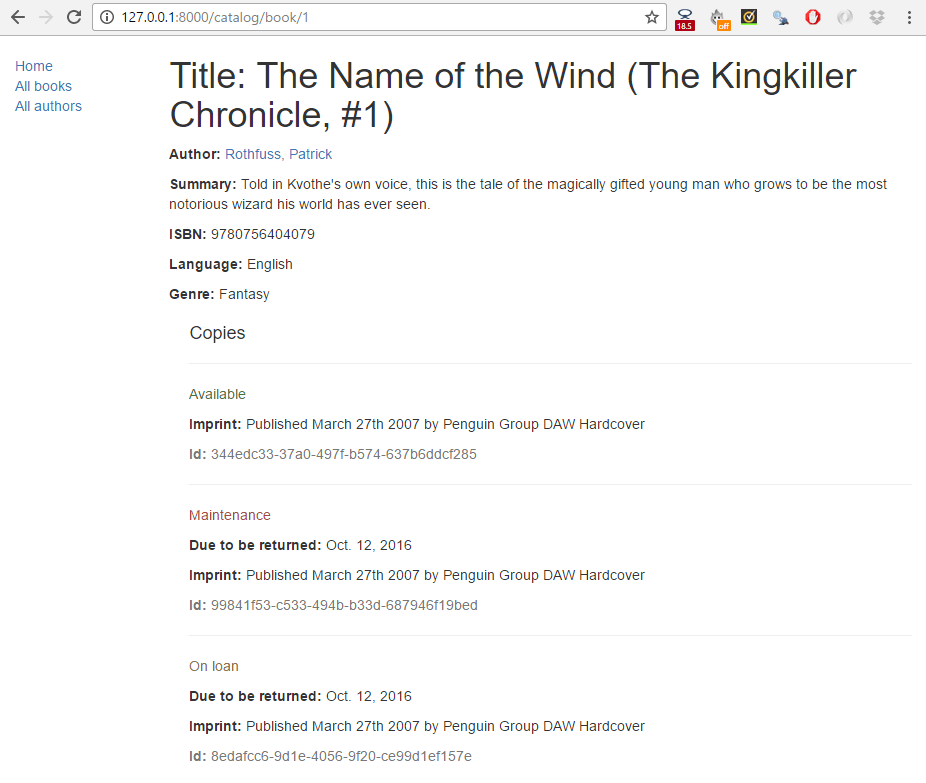
La page de détail d'un livre va afficher les informations sur un livre précis, auquel on accède en utilisant l'URL catalog/book/<id> (où <id> est la clé primaire pour le livre). En plus des champs définis dans le modèle Book (auteur, résumé, ISBN, langue et genre), nous allons aussi lister les détails des copies disponibles (BookInstances), incluant le statut, la date de retour prévue, la marque d'éditeur et l'id. Cela permettra à nos lecteurs, non seulement de s'informer sur le livre, mais aussi de confirmer si et quand il sera disponible.
Mappage d'URL
Ouvrez /catalog/urls.py et ajoutez-y le mappeur d'URL 'book-detail' indiqué en gras ci-dessous. Cette fonction path() définit un pattern, la vue générique basée sur classe qui lui est associée, ainsi qu'un nom.
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
path('book/<int:pk>', views.BookDetailView.as_view(), name='book-detail'),
]
Pour le chemin book-detail, le pattern d'URL utilise une syntaxe spéciale pour capturer l'id exact du livre que nous voulons voir. La syntaxe est très simple : les chevrons ('<' et '>') définissent la partie de l'URL qui doit être capturée et encadrent le nom de la variable que la vue pourra utiliser pour accéder aux données capturées. Par exemple, <something> va capturer le pattern marqué et passer la valeur à la vue en tant que variable "something". De manière optionnelle, vous pouvez faire précéder le nom de variable d'une spécification de convertisseur, qui définit le type de la donnée (int, str, slug, uuid, path).
Dans ce cas, nous utilisons '<int:pk>' pour capturer l'id du livre, qui doit être une chaîne formatée d'une certaine manière, et passer cet id à la vue en tant que paramètre nommé pk (abréviation pour primary key - clé primaire). C'est l'id qui doit être utilisé pour stocker le livre de manière unique dans la base de données, comme défini dans le modèle Book.
Note : Comme nous l'avons dit précédemment, notre URL correcte est en réalité catalog/book/<digits> (comme nous sommes dans l'application catalog, /catalog/ est supposé).
Attention : La vue générique basée sur classe "détail" s'attend à recevoir un paramètre appelé pk. Si vous écrivez votre propre fonction, vous pouvez utiliser le nom que vous voulez pour votre paramètre, ou même passer l'information avec un argument non nommé.
Introduction aux chemins et expressions régulières avancés
Note : Vous n'aurez pas besoin de cette section pour achever le tutoriel ! Nous en parlons parce que nous savons que cette option vous sera probablement utile dans votre avenir centré sur Django.
La recherche de pattern fournie par path() est simple et utile pour les cas (très communs) où vous voulez seulement capturer n'importe quelle chaîne ou entier. Si vous avez besoin d'un filtre plus affiné (par exemple pour filtrer seulement les chaînes qui ont un certain nombre de caractères), alors vous pouvez utiliser la méthode re_path().
Cette méthode est utilisée exactement comme path(), sauf qu'elle vous permet de spécifier un pattern utilisant une Expression régulière. Par exemple, le chemin précédent pourrait avoir été écrit ainsi :
re_path(r'^book/(?P<pk>\d+)$', views.BookDetailView.as_view(), name='book-detail'),
Les expressions régulières sont un outil de recherche de pattern extrêmement puissant. Ils sont, il est vrai, assez peu intuitifs et peuvent se révéler intimidants pour les débutants. Ci-dessous vous trouverez une introduction très courte !
La première chose à savoir est que les expressions régulières devraient ordinairement être déclarées en utilisant la syntaxe "chaîne littérale brute" (c'est-à-dire encadrées ainsi : r'<votre texte d'expression régulière va ici>').
L'essentiel de ce que vous aurez besoin de savoir pour déclarer une recherche de pattern est contenu dans le tableau qui suit :
| Symbol | Meaning |
|---|---|
| ^ | Recherche le début du texte. |
| $ | Recherche la fin du texte. |
| \d | Recherche un digit (0, 1, 2, ... 9). |
| \w | Recherche un caractère de mot, c'est-à-dire tout caractère dans l'alphabet (majuscule ou minuscule), un digit ou un underscore (_). |
| + | Recherche au moins une occurrence du caractère précédent. Par exemple, pour rechercher au moins 1 digit, vous utiliseriez \d+. Pour rechercher au moins 1 caractère "a", vous utiliseriez a+. |
| * | Recherche zéro ou plus occurrence(s) du caractère précédent. Par exemple, pour rechercher "rien ou un mot", vous pourriez utiliser \w*. |
| ( ) | Capture la partie du pattern contenue dans les parenthèses. Toutes les valeurs capturées seront passées à la vue en tant que paramètres non nommés (si plusieurs patterns sont capturés, les paramètres associés seront fournis dans l'ordre de déclaration des captures). |
| (?P<name>...) | Capture le pattern (indiqué par…) en tant que variable nommée (dans ce cas "name"). Les valeurs capturées sont passées à la vue avec le nom spécifié. Votre vue doit par conséquent déclarer un argument avec le même nom ! |
| [ ] | Recherche l'un des caractères contenus dans cet ensemble. Par exemple, [abc] va rechercher "a" ou "b" ou "c". [-\w] va rechercher le caractère "-" ou tout caractère de mot. |
La plupart des autres caractères peuvent être pris littéralement.
Considérons quelques exemples réels de patterns :
| Pattern | Description |
|---|---|
| r'^book/(?P<pk>\d+)$' |
C'est là l'expression régulière utilisée dans notre mappeur d'URL.
Elle recherche une chaîne qui a Elle capture aussi tous les digits (?P<pk>\d+) et les passe à la vue dans un paramètre appelé 'pk'. Les valeurs capturées sont toujours passées comme des chaînes !
Par exemple, cette expression régulière trouverait une correspondance
dans l'URL |
| r'^book/(\d+)$' |
Ceci recherche la même URL que dans le cas précédent. L'information capturée serait envoyée à la vue en tant qu'argument non nommé. |
| r'^book/(?P<stub>[-\w]+)$' |
Ceci recherche une chaîne qui a
Ceci est un pattern relativement typique pour un "stub". Les stubs
sont des clés primaires basées sur des mots (plus agréables que des
IDs) pour retrouver des données. Vous pouvez utiliser un stub si vous
voulez que votre URL de livre contienne plus d'informations. Par
exemple |
Vous pouvez capturer plusieurs patterns en une seule fois, et donc encoder beaucoup d'informations différentes dans l'URL.
Note : Comme défi, essayez d'envisager comment vous devriez encoder une URL pour lister tous les livres sortis en telle année, à tel mois et à tel jour, et l'expression régulière qu'il faudrait utiliser pour la rechercher.
Passer des options supplémentaires dans vos mappages d'URL
Une fonctionnalité que nous n'avons pas utilisée ici, mais que vous pourriez trouver valable, c'est que vous pouvez passer à la vue des options supplémentaires. Les options sont déclarées comme un dictionnaire que vous passez comme troisième argument (non nommé) à la fonction path(). Cette approche peut être utile si vous voulez utiliser la même vue pour des ressources multiples, et passer des données pour configurer son comportement dans chaque cas (ci-dessous nous fournissons un template différent dans chaque cas).
path('url/', views.my_reused_view, {'my_template_name': 'some_path'}, name='aurl'),
path('anotherurl/', views.my_reused_view, {'my_template_name': 'another_path'}, name='anotherurl'),
Note : Les options supplémentaires aussi bien que les patterns capturés sont passés à la vue comme arguments nommés. Si vous utilisez le même nom pour un pattern capturé et une option supplémentaire, alors seul la value du pattern capturé sera envoyé à la vue (la valeur spécifiée dans l'option supplémentaire sera abandonnée).
Vue (basée sur classe)
Ouvrez catalog/views.py, et copiez-y le code suivant à la fin du fichier :
class BookDetailView(generic.DetailView):
model = Book
C'est tout ! La seule chose que vous avez à faire maintenant, c'est créer un template appelé /locallibrary/catalog/templates/catalog/book_detail.html, et la vue va lui passer les informations de la base de donnée concernant l'enregistrement Book spécifique, extrait par le mapper d'URL. À l'intérieur du template, vous pouvez accéder à la liste de livres via la variable de template appelée object OU book (c'est-à-dire, de manière générique, "le_nom_du_modèle").
Si vous en avez besoin, vous pouvez changer le template utilisé et le nom de l'objet-contexte utilisé pour désigner le livre dans le template. Vous pouvez aussi renommer les méthodes pour, par exemple, ajouter des informations supplémentaires au contexte.
Que se passe-t-il si l'enregistrement n'existe pas ?
Si l'enregistrement demandé n'existe pas, alors la vue générique basée sur classe "détail" va lever automatiquement pour vous une exception Http404 — en production, cela va automatiquement afficher une page appropriée "ressource non trouvée", que vous pouvez personnaliser si besoin.
Juste pour vous donner une idée de la manière dont tout cela fonctionne, le morceau de code ci-dessous montre comment vous implémenteriez cette vue comme une fonction si vous n'utilisiez pas la vue générique basée sur classe "détail".
def book_detail_view(request, primary_key):
try:
book = Book.objects.get(pk=primary_key)
except Book.DoesNotExist:
raise Http404('Book does not exist')
return render(request, 'catalog/book_detail.html', context={'book': book})
La vue essaie d'abord d'obtenir du modèle l'enregistrement correspondant au livre spécifié. Si cela échoue, la vue devrait lever une exception Http404 pour indiquer que le livre est "non trouvé". L'étape finale est ensuite, comme d'habitude, d'appeler render() avec le nom du template et les données concernant le livre dans le paramètre context (comme un dictionnaire).
Une alternative consiste à utiliser la fonction get_object_or_404() comme un raccourci pour lever une exception Http404 si l'enregistrement n'existe pas.
from django.shortcuts import get_object_or_404
def book_detail_view(request, primary_key):
book = get_object_or_404(Book, pk=primary_key)
return render(request, 'catalog/book_detail.html', context={'book': book})
Créer le template de la Vue Détail
Créez le fichier HTML /locallibrary/catalog/templates/catalog/book_detail.html, et copiez-y le code ci-dessous. Comme on l'a dit plus haut, c'est là le nom de template attendu par défaut par la vue générique basée sur classe detail (pour un modèle appelé Book dans une application appelée catalog).
{% extends "base_generic.html" %}
{% block content %}
<h1>Title: {{ book.title }}</h1>
<p><strong>Author:</strong> <a href="">{{ book.author }}</a></p> <!-- author detail link not yet defined -->
<p><strong>Summary:</strong> {{ book.summary }}</p>
<p><strong>ISBN:</strong> {{ book.isbn }}</p>
<p><strong>Language:</strong> {{ book.language }}</p>
<p><strong>Genre:</strong> {{ book.genre.all|join:", " }}</p>
<div style="margin-left:20px;margin-top:20px">
<h4>Copies</h4>
{% for copy in book.bookinstance_set.all %}
<hr>
<p class="{% if copy.status == 'a' %}text-success{% elif copy.status == 'm' %}text-danger{% else %}text-warning{% endif %}">
{{ copy.get_status_display }}
</p>
{% if copy.status != 'a' %}
<p><strong>Due to be returned:</strong> {{ copy.due_back }}</p>
{% endif %}
<p><strong>Imprint:</strong> {{ copy.imprint }}</p>
<p class="text-muted"><strong>Id:</strong> {{ copy.id }}</p>
{% endfor %}
</div>
{% endblock %}
Note : Le lien vers l'auteur dans le template ci-dessus est vide, parce que nous n'avons pas encore crée de page détail pour un auteur. Une fois que cette page sera créée, vous pourrez remplacer l'URL par ceci :
<a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a>
Bien qu'en un peu plus grand, presque tout ce qu'il y a dans ce template a été décrit précédemment :
- Nous étendons notre template de base et récrivons le block "content".
- Nous utilisons une procédure conditionnelle pour déterminer s'il faut ou non afficher tel contenu spécifique.
- Nous utilisons une boucle
forpour boucler sur des listes d'objets. - Nous accédons aux champs du contexte en utilisant la notation à point (parce que nous avons utilisé la vue générique detail, le contexte est nommé
book; nous pourrions aussi utiliser "object").
Une chose intéressante que nous n'avons pas encore vue, c'est la fonction book.bookinstance_set.all(). Cette méthode est "automagiquement" construite par Django pour retourner l'ensemble des enregistrements BookInstance associés à un Book particulier.
{% for copy in book.bookinstance_set.all %}
<!-- code to iterate across each copy/instance of a book -->
{% endfor %}
Cette méthode est requise parce que vous déclarez un champ ForeignKey (one-to-many) seulement du côté "one" de la relation. Comme vous ne faites rien pour déclarer la relation dans les modèles opposés ("many"), Django n'a pas de champ pour récupérer l'ensemble des enregistrements associés. Pour remédier à ce problème, Django construit une fonction justement nommée "recherche inversée", que vous pouvez utiliser. Le nom de la fonction est construit en mettant en minuscule le nom du modèle où a été déclarée la ForeignKey, suivi de _set (ainsi la fonction créée dans Book est bookinstance_set()).
Note : Ici nous utilisons all() pour récupérer tous les enregistrements (comportement par défaut). Bien que vous puissiez utiliser la méthode filter() pour obtenir un sous-ensemble d'enregistrements dans le code, vous ne pouvez faire cela directement dans le template, parce que vous ne pouvez pas spécifier d'arguments dans les fonctions.
Prenez garde également que, si vous ne définissez pas un ordre (dans votre vue basée sur classe ou votre modèle), vous allez voir des erreurs de ce genre en provenance du serveur de développement :
[29/May/2017 18:37:53] "GET /catalog/books/?page=1 HTTP/1.1" 200 1637 /foo/local_library/venv/lib/python3.5/site-packages/django/views/generic/list.py:99: UnorderedObjectListWarning: Pagination may yield inconsistent results with an unordered object_list: <QuerySet [<Author: Ortiz, David>, <Author: H. McRaven, William>, <Author: Leigh, Melinda>]> allow_empty_first_page=allow_empty_first_page, **kwargs)
Ceci vient du fait que l'objet paginator s'attend à ce qu'un ORDER BY soit exécuté sur votre base de données sous-jacente. Sans cela il ne peut pas être sûr que les enregistrements retournés sont vraiment dans le bon ordre !
Ce tutoriel n'a pas (encore !) traité de la pagination, mais comme vous ne pouvez pas utiliser sort_by() et passer un paramètre (pour la même raison que le filter() décrit précédemment), vous avez le choix entre trois options :
- Ajouter un
orderinglors de la déclaration de laclass Metadans votre modèle. - Ajouter un attribut
querysetdans votre vue personnalisée basée sur classe, en spécifiant unorder_by(). - Ajouter une méthode
get_querysetà votre vue personnalisée basée sur classe, et préciser de même unorder_by().
Si vous décidez d'ajouter une class Meta au modèle Author (solution peut-être pas aussi flexible que personnaliser la vue basée sur classe, mais assez facile), vous allez vous retrouver avec quelque chose de ce genre :
class Author(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
date_of_birth = models.DateField(null=True, blank=True)
date_of_death = models.DateField('Died', null=True, blank=True)
def get_absolute_url(self):
return reverse('author-detail', args=[str(self.id)])
def __str__(self):
return f'{self.last_name}, {self.first_name}'
class Meta:
ordering = ['last_name']
Bien sûr le champ n'est pas forcément last_name : ce pourrait être un autre champ.
Dernier point, mais non le moindre : vous devriez trier les données par un attribut/colonne qui a réellement un index (unique ou pas) dans votre base de données, afin d'éviter des problèmes de performance. Bien sûr ce n'est pas requis ici (ce serait un peu exagéré avec si peu de livres et d'utilisateurs), mais il vaut mieux avoir cela à l'esprit pour de futurs projets.
À quoi cela ressemble-t-il ?
À ce point, nous devrions avoir créé tout ce qu'il faut pour afficher à la fois la liste des livres et les pages de détail pour chaque livre. Lancez le serveur (python3 manage.py runserver) et ouvrez votre navigateur à l'adresse http://127.0.0.1:8000/.
Attention : Ne cliquez pas sur les liens vers le détail des auteurs : vous allez les créer lors du prochain défi !
Cliquez sur le lien Tous les livres pour afficher la liste des livres.
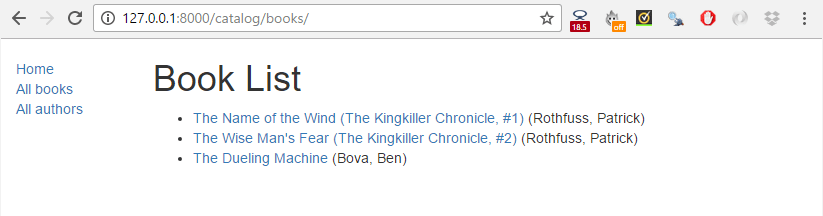
Ensuite cliquez sur un lien dirigeant vers l'un de vos livres. Si tout est réglé correctement, vous allez voir quelque chose de semblable à la capture d'écran suivante :
Pagination
Si vous avez seulement quelques enregistrements, notre page de liste de livres aura une bonne apparence. Mais si vous avez des dizaines ou des centaines d'enregistrements, la page va progressivement devenir plus longue à charger (et aura beaucoup trop de contenu pour naviguer de manière raisonnable). La solution à ce problème est d'ajouter une pagination à vos vues listes, en réduisant le nombre d'éléments affichés sur chaque page.
Django a d'excellents outils pour la pagination. Mieux encore, ces outils sont intégrés dans les vues listes génériques basées sur classes, aussi n'avez-vous pas grand-chose à faire pour les activer !
Vues
Ouvrez catalog/views.py, et ajoutez la ligne paginate_by, en gras ci-dessous.
class BookListView(generic.ListView):
model = Book
paginate_by = 10
Avec cet ajout, dès que vous aurez plus de 10 enregistrements, la vue démarrera la pagination des données qu'elle envoie au template. Les différentes pages sont obtenues en utilisant le paramètre GET : pour obtenir la page 2, vous utiliseriez l'URL /catalog/books/?page=2.
Templates
Maintenant que les données sont paginées, nous avons besoin d'ajouter un outil au template pour parcourir l'ensemble des résultats. Et parce que nous voudrons sûrement faire cela pour toutes les listes vues, nous allons le faire d'une manière qui puisse être ajoutée au template de base.
Ouvrez /locallibrary/catalog/templates/base_generic.html, et copiez-y, sous notre bloc de contenu, le bloc de pagination suivant (mis en gras ci-dessous). Le code commence par vérifier si une pagination est activée sur la page courante. Si oui, il ajoute les liens "précédent" et "suivant" appropriés (et le numéro de la page courante).
{% block content %}{% endblock %}
{% block pagination %}
{% if is_paginated %}
<div class="pagination">
<span class="page-links">
{% if page_obj.has_previous %}
<a href="{{ request.path }}?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="page-current">
Page {{ page_obj.number }} of {{ page_obj.paginator.num_pages }}.
</span>
{% if page_obj.has_next %}
<a href="{{ request.path }}?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endif %}
{% endblock %}
Le page_obj est un objet Paginator qui n'existera que si une pagination est utilisée dans la page courante. Cet objet vous permet de récupérer toutes les informations sur la page courante, les pages précédentes, combien il y a de pages au total, etc.
Nous utilisons {{ request.path }} pour récupérer l'URL de la page courante, afin de créer les liens de pagination. Cela est utile, car cette variable est indépendante de l'objet que nous sommes en train de paginer.
C'est tout !
À quoi cela ressemble-t-il ?
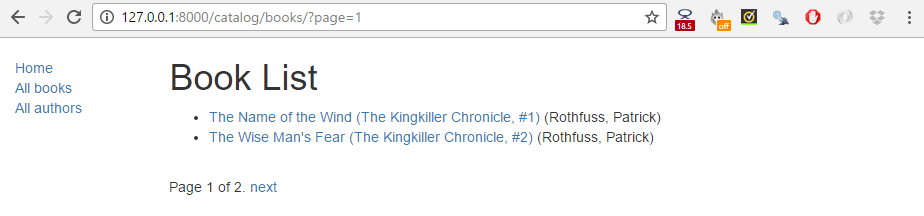
La capture d'écran ci-dessous montre à quoi ressemble la pagination. Si vous n'avez pas entré plus de 10 titres dans votre base de données, vous pouvez tester plus facilement cette pagination en diminuant le nombre spécifié à la ligne paginate_by dans votre fichier catalog/views.py. Pour obtenir le résultat ci-dessous, nous avons changé la ligne en paginate_by = 2.
Les liens de pagination sont affichés en bas de la page, avec les liens suivant/précédent affichés selon la page sur laquelle nous nous trouvons.
Mettez-vous vous-même au défi !
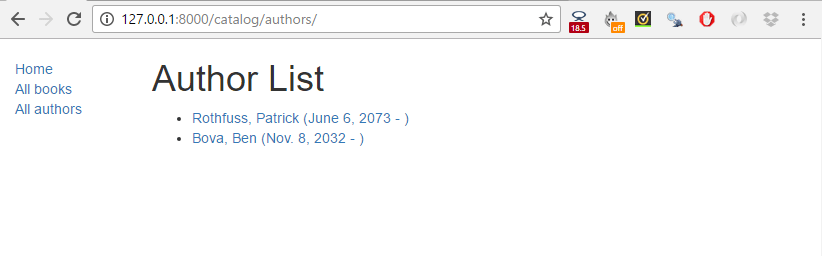
Le challenge dans cet article consiste à créer les vues détail et liste nécessaires à l'achèvement du projet. Ces pages devront être accessibles aux URLs suivantes :
catalog/authors/— La liste de tous les auteurs.catalog/author/<id>— La vue détail pour un auteur précis, avec un champ clé-primaire appelé<id>.
Le code requis pour le mappeur d'URL et les vues sera virtuellement identique aux vues liste et détail du modèle Book, créées ci-dessus. Les templates seront différents, mais auront un comportement semblable.
Note :
- Une fois que vous aurez créé le mappeur d'URL pour la page "liste d'auteurs", vous aurez besoin de mettre aussi à jour le lien All authors dans le template de base. Suivez la même procédure que celle adoptée quand nous avons mis à jour le lien All books.
- Une fois créé le mappeur d'URL pour la page de détails sur l'auteur, vous devrez aussi mettre à jour le template de la vue détail d'un livre (/locallibrary/catalog/templates/catalog/book_detail.html), de sorte que le lien vers l'auteur pointe vers votre nouvelle page de détails sur l'auteur (au lieu d'être une URL vide). La ligne va avoir comme changement la balise montrée en gras ci-dessous.
django
<p> <strong>Author:</strong> <a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a> </p>
Quand vous aurez fini, vos pages vont ressembler aux captures d'écran suivantes.
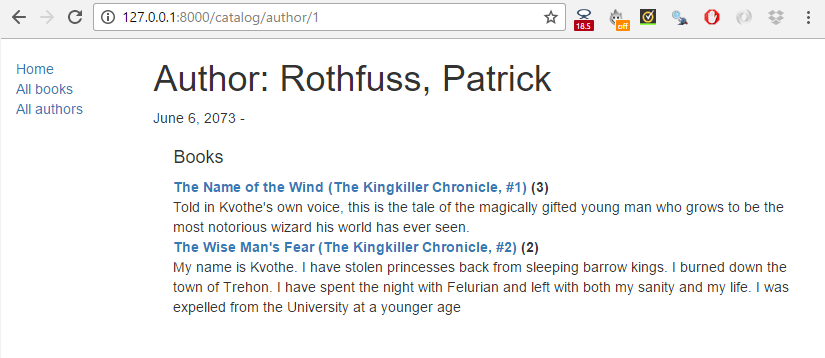
Résumé
Félicitations ! Notre application basique pour bibliothèque est maintenant terminée.
Dans cet article, nous avons appris comment utiliser les vues génériques basées sur classe "liste" et "détail", et nous les avons utilisées pour créer des pages permettant de voir nos livres et nos auteurs. Au passage nous avons appris la recherche d'un pattern d'URL grâce aux expressions régulières, et la manière de passer des données depuis les URLs vers les vues. Nous avons aussi appris quelques trucs supplémentaires pour mieux utiliser les templates. Et en dernier nous vous avons montré comment paginer les vues liste, de façon à pouvoir gérer des listes même avec beaucoup d'enregistrements.
Dans les articles que nous vous présenterons ensuite, nous améliorerons cette application pour intégrer des comptes utilisateurs, et nous allons donc vous montrer comment gérer l'authentification des utilisateurs, les permissions, les sessions et les formulaires.
Voyez aussi
- Built-in class-based generic views (Django docs)
- Generic display views (Django docs)
- Introduction to class-based views (Django docs)
- Built-in template tags and filters (Django docs).
- Pagination (Django docs)