Web Audio API의 기본 개념
오디오가 어떻게 여러분의 앱을 통해서 전송(route)되는지를 설계하는 동안 여러분이 적절한 결정을 내리는 것을 돕기 위해, 이 문서는 Web Audio API의 기능이 어떻게 동작하는가를 뒷받침하는 얼마간의 오디오 이론을 설명합니다. 이 문서를 읽는다고 해서 여러분이 숙련된 사운드 엔지니어가 될 수는 없지만, 왜 Web Audio API가 이렇게 동작하는지를 이해하기에 충분한 배경지식을 줄 것입니다.
오디오 그래프
Web Audio API는 오디오 컨텍스트(audio context) 내의 오디오 연산을 다루는 것을 포함하고, 모듈러 라우팅(modular routing)을 허용하도록 설계되었습니다. 기본적인 오디오 연산은 오디오 노드(audio node)와 함께 수행되는데, 이는 오디오 라우팅 그래프를 형성하기 위해 함께 연결되어 있습니다. 다른 유형의 채널 레이아웃을 가진 몇몇의 소스(source)들은 심지어 하나의 컨텍스트 내에서 지원됩니다. 이 모듈식의(modular) 디자인은 역동적인 효과를 가진 복잡한 오디오 기능을 만드는 데 있어 유연함을 제공합니다.
하나 또는 더 많은 소스에서 시작하고, 하나 또는 더 많은 노드를 통과하고, 그리고서 도착지(destination)에서 끝나는 체인(chain)을 형성하며, 오디오 노드는 입력과 출력을 통해 연결되어 있습니다. 그러나, 예를 들어 여러분이 단지 오디오 데이터를 시각화하기를 원한다면 도착지를 반드시 제공할 필요는 없습니다. 웹 오디오의 단순하고, 일반적인 작업 흐름은 다음과 같습니다:
- 오디오 컨텍스트를 생성합니다.
- 컨텍스트 내에서, 다음과 같이 소스를 생성합니다 —
<audio>(en-US), oscillator, 또는 stream. - 효과 노드를 생성하는데, 예를 들자면 reverb, biquad filter, panner, 또는 compressor가 있습니다.
- 사용자의 컴퓨터 스피커와 같이, 오디오의 최종 도착지를 선택합니다.
- 오디오 소스로부터 0 또는 더 많은 효과를 거쳐 연결(connection)을 확립하는데, 마지막으로는 앞서 선택된 도착지에서 끝납니다.
참고: 한 신호에서 사용 가능한 오디오 채널의 숫자는 종종 숫자 형식으로 표현되는데, 예를 들자면 2.0 또는 5.1과 같습니다. 이것은 채널 표기법이라고 불립니다. 첫번째 숫자는 신호가 포함하는 전체 주파수 범위 오디오 채널의 숫자입니다. 마침표 뒤의 숫자는 저주파 효과(LFE) 출력에 대해 비축된 채널의 수를 나타냅니다; 이 숫자는 종종 서브 우퍼(subwoofer)로 불립니다.

각각의 입력 또는 출력은 몇몇의 채널으로 구성되어 있는데, 이는 특정한 오디오 레이아웃을 나타냅니다. 모노, 스테레오, quad, 5.1 등등을 포함하는, 어떠한 별개의 채널 구조든 지원됩니다.
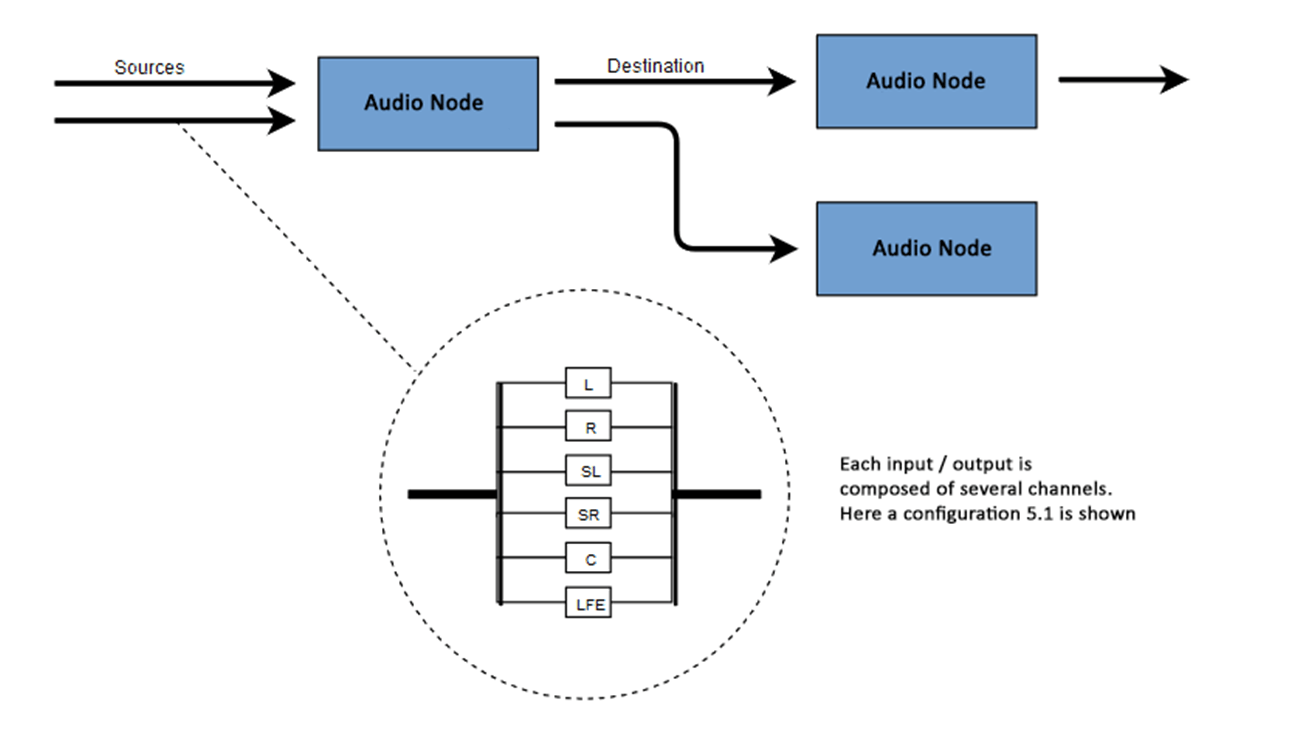
오디오 소스는 다양한 방법으로 얻어질 수 있습니다:
- 소리는 JavaScript에서 (oscillator처럼) 오디오 노드에 의해 직접적으로 생성될 수 있습니다.
- 가공되지 않은(raw) PCM 데이터로부터 생성될 수 있습니다 (오디오 컨텍스트는 지원되는 오디오 포맷을 디코드하는 메서드를 가지고 있습니다).
- (
<video>또는<audio>(en-US)처럼) HTML 미디어 요소로부터 취해질 수 있습니다. - (웹캠이나 마이크처럼) WebRTC
MediaStream(en-US)로부터 직접적으로 취해질 수 있습니다.
오디오 데이터: 무엇이 샘플 속에 들어있는가
오디오 신호가 처리될 때, 샘플링이란 연속 신호(continuous signal)의 불연속 신호(discrete signal)로의 전환을 의미합니다; 또는 달리 말하면, 라이브로 연주하고 있는 밴드와 같이, 연속적인 음파를 컴퓨터가 오디오를 구별되는 단위로 다룰 수 있게 허용하는 일련의 샘플들로 전환하는 것을 의미합니다.
더 많은 정보는 위키피디아 문서 샘플링 (신호 처리)에서 찾을 수 있습니다.
오디오 버퍼: 프레임, 샘플, 그리고 채널
AudioBuffer는 매개변수로서 채널의 수 (1은 모노, 2는 스테레오 등), 버퍼 내부의 샘플 프레임의 수를 의미하는 길이, 그리고 초당 재생되는 샘플 프레임의 수인 샘플 레이트를 취합니다.
샘플은 특정한 채널(스테레오의 경우, 왼쪽 또는 오른쪽)에서, 각각의 특정한 시점에의 오디오 스트림의 값을 표현하는 단일의 float32 값입니다. 프레임 또는 샘플 프레임은, 특정한 시점에 재생될 모든 채널의 모든 값들의 집합입니다: 즉 같은 시간에 재생되는 모든 채널의 모든 샘플 (스테레오 사운드의 경우 2개, 5.1의 경우 6개 등)입니다.
샘플 레이트는 Hz로 측정되는, 1초에 재생될 이 샘플들 (또는 프레임들, 왜냐하면 한 프레임의 모든 샘플들이 같은 시간에 재생되므로) 의 수입니다. 샘플 레이트가 높을수록 음질이 더 좋습니다.
모노와 스테레오 오디오 버퍼를 살펴봅시다, 각각 1초 길이고, 44100Hz로 재생됩니다:
- 모노 버퍼는 44100 샘플과, 44100 프레임을 가질 것입니다.
length프로퍼티는 44100이 될 것입니다. - 스테레오 버퍼는 88200 샘플을 가질 것이나, 여전히 44100 프레임입니다.
length프로퍼티는 프레임의 수와 동일하므로 여전히 44100일 것입니다.

버퍼가 재생될 때, 여러분은 제일 왼쪽의 샘플 프레임을 들을 것이고, 그리고서 다음에 있는 제일 오른쪽의 샘플 프레임 등등을 들을 것입니다. 스테레오의 경우에, 여러분은 양 채널을 동시에 들을 것입니다. 샘플 프레임은 대단히 유용한데, 왜냐하면 샘플 프레임은 채널의 수에 독립적이고, 정밀한 오디오 조작을 함에 있어 유용한 방법으로 시간을 나타내기 때문입니다.
참고: 프레임 카운트로부터 초로 시간을 얻기 위해서는, 프레임의 수를 샘플 레이트로 나누십시오. 샘플의 수로부터 프레임의 수를 얻기 위해서는, 채널 카운트로 나누십시오.
두 개의 간단한 예제입니다:
var context = new AudioContext();
var buffer = context.createBuffer(2, 22050, 44100);
참고: 디지털 오디오에서, 44,100 Hz (또한 44.1 kHz로 표현되어짐) 은 일반적인 샘플링 주파수입니다. 왜 44.1kHz일까요?
첫째로, 왜냐하면 인간의 가청 범위(hearing range)는 대략적으로 20 Hz에서 20,000 Hz이기 때문입니다. 표본화 정리(Nyquist–Shannon sampling theorem)에 의하여, 샘플링 주파수는 반드시 재생하기를 원하는 최대 주파수의 2배보다 커야 합니다. 그러므로, 샘플링 레이트는 40 kHz보다 커야만 합니다.
둘째로, 신호는 반드시 샘플링 전에 저주파 통과 필터(low-pass filter)를 거쳐야만 합니다, 그렇지 않으면 에일리어싱(aliasing)이 발생합니다. 이상적인 저주파 통과 필터는 완벽히 20 kHz 아래의 주파수들을 (약화시키는 일 없이) 통과시키고 완벽히 20 kHz 위의 주파수들을 잘라낼 것이지만, 실제로는 천이 대역(transition band)이 필수적인데, 여기서 주파수들은 부분적으로 약화됩니다. 천이 대역이 넓을수록, 주파수 중복방지 필터(anti-aliasing filter)를 만들기 쉽고 경제적입니다. 44.1 kHz 샘플링 주파수는 2.05 kHz 천이 대역을 감안합니다.
만약 위의 이 호출을 사용한다면, 여러분은 44100Hz (아주 일반적입니다, 대부분의 보통 사운드 카드는 이 레이트에서 실행됩니다) 에서 실행되는 AudioContext에서 재생될 때 0.5초동안 지속될 두 개의 채널을 가진 스테레오 버퍼를 얻을 것입니다. (22050 프레임 / 44100Hz = 0.5초)
var context = new AudioContext();
var buffer = context.createBuffer(1, 22050, 22050);
만약 이 호출을 사용한다면, 여러분은 44100Hz에서 실행되는 AudioContext에서 재생될 때 자동적으로 44100Hz로 리샘플(resample)되고 1.0초동안 지속될 단지 하나의 채널을 가진 모노 버퍼를 얻을 것입니다. (44100 프레임 / 44100Hz = 1초)
참고: 오디오 리샘플링은 이미지 리사이징과 몹시 유사합니다. 예를 들어 여러분이 16 x 16 이미지를 가지고 있지만 32 x 32 영역을 채우고 싶다고 가정해 봅시다. 당신은 리사이즈 (또는 리샘플) 합니다. 결과는 더 낮은 품질을 가지지만 (리사이징 알고리즘에 따라서, 흐릿하거나 각질 수 있습니다), 리사이즈된 이미지가 더 적은 공간을 차지한 채로 작동은 합니다. 리샘플된 오디오는 정확히 동일합니다: 여러분은 공간을 저장하지만, 실제로는 높은 주파수의 콘텐츠 또는 고음의 소리를 적절히 재생할 수 없을 것입니다.
평면(planar) 대 인터리브(interleaved) 버퍼
Web Audio API는 평면 버퍼 포맷을 사용합니다. 왼쪽과 오른쪽 채널은 다음과 같이 저장됩니다:
LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR (16 프레임의 버퍼에 대해)
이것은 오디오 프로세싱에서 아주 일반적입니다: 이것은 각 채널을 독립적으로 처리하기 쉽게 만들어줍니다.
대안은 인터리브 버퍼 포맷을 사용하는 것입니다:
LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR (16 프레임의 버퍼에 대해)
이 포맷은 많은 프로세싱 없이 오디오를 저장하고 재생하는 데 아주 일반적인데, 예를 들자면 디코드된 MP3 스트림이 있습니다.
Web Audio API는 오직 평면 버퍼만을 드러내는데, 왜냐하면 프로세싱을 위해 만들어졌기 때문입니다. 이것은 평면으로 동작하나, 오디오가 재생을 위해 사운드 카드에 전달되었을 때 인터리브로 전환합니다. 역으로, MP3가 디코드되었을 때, 이것은 인터리브 포맷으로 시작하나, 프로세싱을 위해 평면으로 전환됩니다.
오디오 채널
다른 오디오 버퍼는 다른 수의 채널을 포함합니다: 간단한 모노(오직 한 개의 채널)와 스테레오(왼쪽과 오른쪽 채널)에서부터, 각 채널에 포함된 다른 사운드 샘플을 가지고 있어 더욱 풍부한 소리 경험을 가능케 하는 quad와 5.1과 같은 더욱 복잡한 것들까지 있습니다. 채널들은 보통 아래의 테이블에 상세히 설명된 표준 약어에 의해 표현됩니다:
| Mono | 0: M: mono |
|---|---|
| Stereo | 0: L: left 1: R: right |
| Quad | 0: L: left 1: R: right 2: SL: surround left 3: SR: surround right |
| 5.1 | 0: L: left 1: R: right 2: C: center 3: LFE: subwoofer 4: SL: surround left 5: SR: surround right |
업믹싱(up-mixing)과 다운믹싱(down-mixing)
채널의 수가 입력과 출력 사이에서 맞지 않을 때, 업 또는 다운 믹싱이 다음의 규칙에 따라 발생합니다. 이는 AudioNode.channelInterpretation 프로퍼티를 speakers 또는 discrete로 설정함으로써 어느 정도 제어될 수 있습니다.
| 해석 | 입력 채널 | 출력 채널 | 믹싱 규칙 |
|---|---|---|---|
스피커 |
1 (Mono) |
2 (Stereo) |
모노에서 스테레오로 업믹스M 입력 채널이 양
출력 채널 (L와 R)에 대해 사용됩니다.output.L = input.M
|
1 (Mono) |
4 (Quad) |
모노에서 quad로 업믹스M 입력 채널이 비
서라운드(non-surround) 출력 채널에 대해 사용됩니다 (L 과
R). 서라운드 출력 채널 (SL 과
SR)은 작동하지 않습니다(silent).output.L = input.M
|
|
1 (Mono) |
6 (5.1) |
모노에서 5.1로 업믹스M 입력 채널이 센터 출력
채널 (C)에 대해 사용됩니다. 모든 다른
채널들(L, R, LFE,
SL, 그리고 SR)은 작동하지 않습니다.output.L = 0output.C = input.M
|
|
2 (Stereo) |
1 (Mono) |
스테레오에서 모노로 다운믹스 양 출력 채널 ( L
과 R)은 고유한 출력 채널 (M)을 생산하기 위해
동등하게 결합됩니다.output.M = 0.5 * (input.L + input.R)
|
|
2 (Stereo) |
4 (Quad) |
스테레오에서 quad로 업믹스L 과
R 입력 채널이 각자의 비 서라운드 출력 채널 (L
과 R)에 대해 사용됩니다. 서라운드 출력 채널 (SL
과 SR) 은 작동하지 않습니다.output.L = input.L
|
|
2 (Stereo) |
6 (5.1) |
스테레오에서 5.1로 업믹스L 과
R 입력 채널이 각자의 비 서라운드 출력 채널 (L
과 R) 에 대해 사용됩니다. 서라운드 출력 채널 (SL
과 SR), 그리고 센터 (C) 와 서브우퍼
(LFE) 채널은 작동하지 않습니다.output.L = input.L
|
|
4 (Quad) |
1 (Mono) |
quad에서 모노로 다운믹스 모든 네 개의 입력 채널 ( L, R, SL, and SR)
이 고유한 출력 채널 (M)을 생산하기 위해 동등하게
결합됩니다.output.M = 0.25 * (input.L + input.R + input.SL + input.SR)
|
|
4 (Quad) |
2 (Stereo) |
quad에서 스테레오로 다운믹스 왼쪽 입력 채널 ( L
과 SL) 둘 다 고유한 왼쪽 출력 채널 (L)을
생산하기 위해 동등하게 결합됩니다. 그리고 유사하게, 오른쪽 입력 채널
(R 과 SR) 둘 다 고유한 오른쪽 출력 채널을
생산하기 위해 동등하게 결합됩니다.output.L = 0.5 * (input.L + input.SL)output.R = 0.5 * (input.R + input.SR)
|
|
4 (Quad) |
6 (5.1) |
quad에서 5.1로 업믹스L, R,
SL, 그리고 SR 입력 채널이 각각의 출력 채널
(L 과 R)에 대해 사용됩니다. 센터
(C)와 서브우퍼 (LFE) 채널은 작동하지 않은 채로
남아있습니다.output.L = input.L
|
|
6 (5.1) |
1 (Mono) |
5.1에서 모노로 다운믹스 왼쪽 ( L 과
SL), 오른쪽 (R 과 SR) 그리고 중앙
채널이 모두 함께 믹스됩니다. 서라운드 채널은 약간 약화되고 regular
lateral 채널은 하나의 채널로 카운트되도록 √2/2를 곱함으로써
파워가 보정(power-compensated)됩니다. 서브우퍼 (LFE) 채널은
손실됩니다.output.M = 0.7071 * (input.L + input.R) + input.C + 0.5 * (input.SL +
input.SR)
|
|
6 (5.1) |
2 (Stereo) |
5.1에서 스테레오로 다운믹스 중앙 채널 ( C)이
각각의 측면 서라운드 채널(SL 또는 SR)과
합계되고 각각의 측면 채널로 믹스됩니다. 두 개의 채널로
다운믹스되었으므로, 더 낮은 파워로 믹스되었습니다: 각각의 경우에
√2/2가 곱해집니다. 서브우퍼 (LFE) 채널은
손실됩니다.output.L = input.L + 0.7071 * (input.C + input.SL)+ 0.7071 * (input.C + input.SR)
|
|
6 (5.1) |
4 (Quad) |
5.1에서 quad로 다운믹스 중앙 ( C) 채널이
측면의 비 서라운드 채널 (L 과 R)과 믹스됩니다.
두 채널로 다운믹스되었으므로, 더 낮은 파워로 믹스되었습니다: 각각의
경우에 √2/2가 곱해집니다. 서라운드 채널은 변경되지 않은
채로 전달됩니다. 서브우퍼 (LFE) 채널은 손실됩니다.output.L = input.L + 0.7071 * input.C
|
|
| 기타 비표준 레이아웃 |
비표준 채널 레이아웃은 channelInterpretation이
discrete로 설정된 것처럼 다뤄집니다.사양(specification)은 분명히 새로운 스피커 레이아웃의 미래의 정의를 허용합니다. 특정한 수의 채널에 대한 브라우저의 행동이 미래에 달라질지도 모르므로 이 대비책은 그러므로 미래에도 사용할 수 있는 (future proof) 것이 아닙니다. |
||
discrete |
any (x) |
x<y인 any (y) |
discrete 채널의 업믹스 대응하는 입력 채널을 가지고 있는 각각의 출력 채널을 채웁니다, 즉 같은 인덱스를 가진 입력 채널입니다. 해당하는 입력 채널이 없는 채널은 작동하지 않은 채로 남아있습니다. |
any (x) |
x>y인 any (y) |
discrete 채널의 다운믹스 대응하는 입력 채널을 가지고 있는 각각의 출력 채널을 채웁니다, 즉 같은 인덱스를 가진 입력 채널입니다. 해당하는 출력 채널을 가지고 있지 않은 입력 채널은 탈락됩니다. |
|
시각화
일반적으로, 오디오 시각화는 보통 진폭 이득(gain) 또는 주파수 데이터인, 시간에 대한 오디오 데이터의 출력에 접근함으로써, 그리고서 그것을 그래프와 같이 시각적 결과로 바꾸기 위해 그래픽 기술을 사용함으로써 성취됩니다. Web Audio API는 통과하는 오디오 신호를 변경하지 않는 AnalyserNode를 가지고 있습니다. 대신 이것은 <canvas>와 같은 시각화 기술로 전달될 수 있는 오디오 데이터를 출력합니다.

여러분은 다음의 메서드들을 사용해 데이터를 얻을 수 있습니다:
AnalyserNode.getFloatFrequencyData()-
현재 주파수 데이터를 이것 안으로 전달된
Float32Array배열 안으로 복사합니다. AnalyserNode.getByteFrequencyData()-
현재 주파수 데이터를 이것 안으로 전달된
Uint8Array(unsigned byte array) 안으로 복사합니다. AnalyserNode.getFloatTimeDomainData()-
현재 파형, 또는 시간 영역(time-domain), 데이터를 이것 안으로 전달된
Float32Array안으로 복사합니다. AnalyserNode.getByteTimeDomainData()-
현재 파형, 또는 시간 영역, 데이터를 이것 안으로 전달된
Uint8Array(unsigned byte array) 안으로 복사합니다.
참고: 더 많은 정보를 보시려면, Web Audio API로 시각화 문서를 참조하세요.
공간화
(Web Audio API의 PannerNode (en-US) 와 AudioListener (en-US) 노드에 의해 다뤄지는) 오디오 공간화는 공간의 어떤 점에서의 오디오 신호의 위치와 행동을 나타내고(model), 청자(listener)가 그 오디오를 들을 수 있게 허용합니다.
panner의 위치는 right-hand 데카르트 좌표 (Cartesian coordinate)로 기술됩니다; 이것의 움직임은 도플러 효과를 생성하는데 필수적인 속도 벡터를 사용하고, 이것의 방향성(directionality)은 방향성 원뿔을 사용합니다. 이 원뿔은 아주 클 수 있는데, 예를 들자면 전방향의 소스(omnidirectional source)에 대한 것일 수 있습니다.

청자의 위치는 right-hand 데카르트 좌표를 사용해 기술됩니다; 이것의 움직임은 속도 벡터를 사용하고 청자의 머리가 향하고 있는 방향은 위와 앞의 두 개의 방향 벡터를 사용합니다. 이것들은 각각 청자의 머리의 위의 방향과, 청자의 코가 가리키고 있는 방향을 정의하며, 서로 직각에 있습니다.
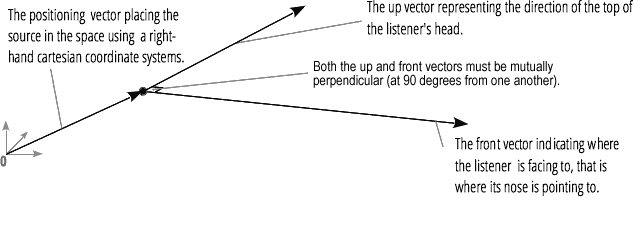
참고: 더 많은 정보를 보시려면, Web audio 공간화 기본 문서를 참조하세요.
팬 인(fan-in)과 팬 아웃(fan-out)
오디오 용어에서, 팬 인은 ChannelMergerNode (en-US)가 일련의 모노 입력 소스를 취하고 단일의 다수 채널 신호를 출력하는 과정을 설명합니다:

팬 아웃은 반대 과정을 설명하는데, ChannelSplitterNode (en-US)가 다수 채널 입력 소스를 취하고 다수의 모노 출력 신호를 출력합니다.
